Numerous processes and standards in Terminals are still country or company specific, and often even depend on the equipment manufacturer. To automate and digitize, this involves tailormade solutions. In the era of AI algorithms fed by big data, customizing for specific use cases could seem contradictory. Dedicated to identifying codes and objects on intermodal assets for Port access automation, AllRead has learned to deal with it, as we illustrate here through a case study in Argentina with Terminal 6.
1. “De su madre y de su padre”
In Spain I heard many times, “every terminal is from its mother and its father” meaning they each have their own processes, systems, infrastructure, best practices and company culture. Despite regulatory frameworks from the International Maritime Organization (IMO), standards from International Container Bureau (BIC) or the International Organisation from standardization (ISO) for instance, we cannot avoid a certain heterogeneity in codifications, certifications and rules that govern terminal operations. Initiatives like the TIC 4.0 Association is dedicated “to promote, define and adopt standards” that drive terminal operations on international level, and there is a long road ahead. Besides, even among the well-known and commonly adopted standards, uncountable nuances exist.
2. To be or not to be…. standardized
Standard codifications, but many shades of gray
Intermodal transport relies on one unnegotiable standard: the intermodal container, or ISO container, which features have been unchanged since decades and make frictionless transshipments possible from ship to road and rail. Looking closer, many types of containers are included by the international standard: 20-foot, 40-foot, 45 foot, tank containers; swap bodies, flats, open tops, reefers… Looking through the eyes of a computer vision engineer, the variability might impact the performance of the algorithms. The codes might respect the same BIC codification, but they are positioned in different places, with different fonts, sizes, and backgrounds.

A more obvious variability are the license plates, which might have to respect transnational standards, like in the European union, but are still very much country specific and require specific trainings. Some illustrative examples are the trailer license plate in Spain, which is red with black characters, involving low contrast, or Moroccan license plates with Arabic alphabet, also present in Europe through RORO vehicles. More exotic are the vehicle license plates that are positioned elsewhere on the truck, like on the on the tractor door, with no rules applied to shape, format, colour or font.

To close the loop, we cannot avoid mentioning the Wagon UIC standards (International Union of Railways). Same as with BIC standards, the UIC codes on wagons can be expressed in many ways. Vertically, horizontally, on an intermodal wagon, a tank car, an auto rack or a container wagon.

Country and company specific codifications
One of our early projects in the port industry was in Vigo Terminal Kaleido (Spain), dealing with import of Granite blocks. Operators had to manually register the codes of the incoming and outgoing blocks of granite from 5 different suppliers abroad. There is no standardization in their letter and number structure, resulting in as many versions as there are operators marking the blocks manually from a spray or stencil, which adds an additional challenge for reading.

In the same context of manufacturer specific codifications, we faced an interesting use case with the German Cargobeamer wagons, specially designed to carry semi-trailers. Beyond the usual UIC related information (wagon code, TARA, wagon length…), more information is specific to the manufacturer: if the Handbrake is on red or green, what is the G/P Lever position, if the “unlock cable” is available or unavailable, the position of the locking pin…

Finally, a more country specific example sends us to Brazil, where the government defined in 2022 (Ordinance RFB No. 143) several measures to be implemented in areas with customs activity. Their goal is to improve the physical controls and the monitoring of goods, like the mandatory installation of automatic data collection systems for goods transiting by road or rail. Applying this to the cellulose transport, important in the region, we discover the specific cellulose wagons, with their unique codification, without any resemblance to the other intermodal freight rail wagons.

3. Machine Learning in Variable Environments
In machine learning, the bias-variance tradeoff is the relationship between a model’s learning capabilities and how well it can make predictions on new data that were not used to train the model. The problem of avoiding that machine learning techniques overfit the training data and loose genericness is often accentuated when dealing with unbalanced situations where some of the elements to recognize are extremely rare while others are too frequent.
For an artificial intelligence model to be deployed in the real world, it is paramount that during training it has reached a sufficient level of abstraction needed to distill the important information from the training data at hand and that it has gained the ability to generalize and infer knowledge beyond the training set, so that it can still perform well when faced with previously unseen data or underrepresented elements. But how to guarantee this ability in an ever-changing and unpredictable environment?

Two main aspects need to be considered when deploying machine learning models into new production environments. First is data quality and locality. Since machine learning models rely on the data they have been trained on, they often are sensitive to the amount and completeness of incoming data. When deploying models to new customers, we need to guarantee that there aren’t any major and significant differences between the local data and the data which the models have been trained on. The second aspect to take into account is the model’s decay. The performance of machine learning models in production can deteriorate over time and they can start to behave abnormally because changes in the real-life input data provoke drifts between the data distribution seen during model training and the operational environment.
To maintain the accuracy and reliability of machine learning models over time it is mandatory to implement Machine learning operations (MLOps) practices that enforce a regular monitoring of the system’s performance. Proactive steps to prevent or mitigate performance losses such as retraining or fine-tuning the model on new data must be taken to overcome model or data drifts. This should be done periodically, but also in response to significant changes in the data, for instance when facing a new client with novel and unseen scenarios.
But it is often the case where we need to face the problem of data scarcity. A new specific element must be recognized, but very few examples of such an item are available at hand. In order to face such a challenge, in AllRead we have an unique stack of Deep Learning solutions that use data augmentation techniques together with synthetic data generation so our models have exposure to a wide and representative range of data, making them more robust and resilient to the variability tha we encounter while having the ability to be fine-tuned for specific ad-hoc scenarios that we face.

Similarly, techniques like transfer learning or domain adaptation, where we have models trained on a source data distribution but applied on a different, but related, target data distribution, help our models to adapt to an ever-changing environment and to tackle specific use cases.
4. Applying Machine Learning in Terminal 6 Argentina
Located on the banks of the Paraná River, Terminal 6 (T6) is the most important agro-industrial export complex in Latin America. The port receives more than 80,000 tons of raw materials daily, which are stored, transformed and finally dispatched to various parts of the world.
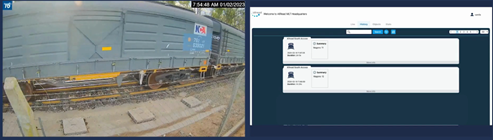
Transport by train represents 33% of the total. The terminal receives around 10 trains loaded with grain daily, counting approximately 50 carriages labelled with their respective identification codes. The wagons must be identified at least two times, when they enter the terminal and when they pass through the weighing scale to be then imputed into the information management systems. This process, done manually, had to be digitalized, given the data collection process represented a bottleneck for T6 and suffered the risk errors.

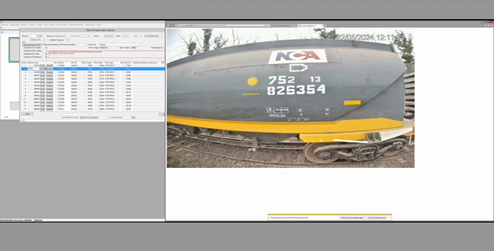
The wagon codes found on these trains are not ISO standards, quite the opposite, unique to this use case, and therefore no robust “from the shelf” solution was available. The system should be able to recognize two different types of codes, in addition to facing quite challenging scenarios in terms of the visibility/readability of these codes, which are often dirty or damaged significantly.

The proposed solution from AllRead involves the deployment of two different AI models. The first is the model devoted to detecting and recognizing the wagon codes (A), while the second model is used to detect wagon separators (couplings) (B). Even though some wagon codes are illegible, we can assemble the correct train map by the combination of those two models in parallel.

In order to quickly provide a working solution to the client, we first deployed our generic scene text recognition models, able to spot and recognize whichever text there is present in the images. An ad-hoc post-processing step then identified the wagon codes from the rest of the extracted text.
This initial implementation yielded results of around 80%. Some of the codes were not correctly detected, and the font used to print the codes in the wagons provoked that often digits ‘5’, ‘6’ and ‘9’ were mistakenly recognized (see images above). Although only a little additional data was available, the models needed to be retrained to tackle the data and model drift that we were facing. We put in place two iterations of the MLOps loop, that involved gathering, but mostly synthetizing new training data, fine-tuning and domain adaptation of our Deep Learning models for text detection and text recognition and performance monitoring. We finally deployed a tailor-made solution for those specific wagon codes that provided accuracies beyond 96% recognition.
The solution proposed by AllRead was perfectly suited to what T6 was looking for. After some iterations over the initial deployed models, and regardless of the challenging scenario, thanks to the robustness of the software and its AI models, AllRead stays true to its philosophy: always ensure minimum hardware requirements: two cameras and two light spots fixed on posts on both side of the lane, and connected to one server.

With the support of Generática, the port’s technology consultants and Partner of AllRead, the solution has been integrated into the information systems and daily tasks of the operators. Considering that at the beginning of 2024, while the weighing process was digital, the monitoring of trains was done manually (that is, for each train that entered, the notes were taken manually to be linked to their respective weights afterwards), one can assume the significant gain in efficiency of automating the data collection and consolidation.
Follow us and subscribe to our newsletter
To keep up to date with AllRead’s news, subscribe to our newsletter. You will periodically receive the most relevant content and news from our blog in your email inbox.
Follow us also on our social profiles on LinkedIn, Twitter and YouTube.