Numerosos procesos y estándares en las terminales siguen siendo específicos de cada país o empresa, e incluso dependen del fabricante del equipo. Para automatizar y digitalizar, esto implica soluciones a medida. En la era de los algoritmos de IA alimentados por grandes volúmenes de datos, la personalización para casos de uso específicos podría parecer contradictoria. Dedicado a la identificación de códigos y objetos en activos intermodales para la automatización del acceso portuario, AllRead ha aprendido a gestionar esta situación, como ilustramos aquí a través de un caso de estudio en Argentina con Terminal 6.
1. «De su madre y de su padre»
En España, he escuchado muchas veces la expresión «cada terminal es de su madre y de su padre», lo que significa que cada una tiene sus propios procesos, sistemas, infraestructura, mejores prácticas y cultura empresarial. A pesar de los marcos regulatorios de la Organización Marítima Internacional (IMO), los estándares del Bureau International des Containers (BIC) o de la Organización Internacional de Normalización (ISO), no se puede evitar cierta heterogeneidad en las codificaciones, certificaciones y normativas que rigen las operaciones de las terminales. Iniciativas como la Asociación TIC 4.0 están dedicadas a «promover, definir y adoptar estándares» que impulsen las operaciones terminales a nivel internacional, pero aún queda un largo camino por recorrer. Además, incluso entre los estándares bien conocidos y ampliamente adoptados, existen innumerables matices.
2. Ser o no ser… estandarizado
Codificaciones estándar, pero con muchas variaciones
El transporte intermodal se basa en un estándar innegociable: el contenedor intermodal o contenedor ISO, cuyas características han permanecido inalteradas durante décadas, permitiendo transbordos fluidos entre barco, carretera y ferrocarril. Sin embargo, dentro del estándar internacional, existen muchos tipos de contenedores: 20 pies, 40 pies, 45 pies, tanques, swap bodies, plataformas, open tops, reefers, entre otros. Desde la perspectiva de un ingeniero de visión artificial, esta variabilidad puede afectar el rendimiento de los algoritmos. Los códigos pueden respetar la codificación del BIC, pero están ubicados en diferentes lugares, con diferentes fuentes, tamaños y fondos.

Otro caso evidente de variabilidad son las matrículas, que pueden estar sujetas a estándares transnacionales, como en la Unión Europea, pero aún así son específicas de cada país y requieren entrenamientos particulares. Algunos ejemplos ilustrativos son las matrículas de remolque en España, que son rojas con caracteres negros, lo que genera bajo contraste, o las matrículas marroquíes con alfabeto árabe, también presentes en Europa a través de vehículos RORO. Más exóticas aún son las matrículas de vehículos que se colocan en diferentes ubicaciones del camión, como en la puerta del tractor, sin reglas fijas sobre forma, formato, color o fuente.

Por último, no podemos dejar de mencionar los estándares UIC de vagones (Unión Internacional de Ferrocarriles). Al igual que con los estándares BIC, los códigos UIC en los vagones pueden expresarse de muchas maneras: verticalmente, horizontalmente, en un vagón intermodal, un vagón cisterna, un autovagón o un vagón portacontenedores.

Codificaciones específicas por país y empresa
Uno de nuestros primeros proyectos en la industria portuaria fue en la Terminal de Vigo Kaleido (España), donde se manejaban bloques de granito importados. Los operadores debían registrar manualmente los códigos de los bloques entrantes y salientes de cinco proveedores diferentes. No existía una estandarización en la estructura de letras y números, lo que resultaba en tantas variaciones como operadores marcando los bloques manualmente con aerosol o plantillas, lo que añadía un desafío adicional para la lectura.

En un contexto similar de codificaciones específicas del fabricante, enfrentamos un caso interesante con los vagones Cargobeamer en Alemania, diseñados para transportar semirremolques. Más allá de la información habitual relacionada con la UIC (código del vagón, TARA, longitud del vagón…), hay información específica del fabricante: si el freno de mano está en rojo o verde, la posición de la palanca G/P, si el «cable de desbloqueo» está disponible o no, la posición del pasador de bloqueo, etc.

Finalmente, un ejemplo específico por país nos lleva a Brasil, donde en 2022 el gobierno estableció medidas para mejorar los controles físicos y la supervisión de mercancías en zonas aduaneras. Aplicado al transporte de celulosa, esto implica vagones de celulosa con una codificación única, sin semejanza con otros vagones de carga intermodal.

3. Machine Learning en Entornos Variables
En el aprendizaje automático, el equilibrio entre sesgo y varianza es la relación entre la capacidad de aprendizaje de un modelo y su capacidad para hacer predicciones con datos nuevos que no se utilizaron para entrenarlo. El problema de evitar que las técnicas de aprendizaje automático se ajusten en exceso a los datos de entrenamiento y pierdan su carácter genérico suele acentuarse cuando se trata de situaciones desequilibradas en las que algunos de los elementos a reconocer son extremadamente raros mientras que otros son demasiado frecuentes.
Para que un modelo de inteligencia artificial pueda desplegarse en el mundo real, es primordial que durante el entrenamiento haya alcanzado un nivel de abstracción suficiente para destilar la información importante de los datos de entrenamiento de que dispone y que haya adquirido la capacidad de generalizar e inferir conocimientos más allá del conjunto de entrenamiento, de modo que pueda seguir obteniendo buenos resultados cuando se enfrente a datos no vistos anteriormente o a elementos infrarrepresentados. Pero, ¿cómo garantizar esta capacidad en un entorno siempre cambiante e imprevisible?

Hay que tener en cuenta dos aspectos principales a la hora de desplegar modelos de aprendizaje automático en nuevos entornos de producción. El primero es la calidad y la localización de los datos. Dado que los modelos de aprendizaje automático se basan en los datos con los que han sido entrenados, suelen ser sensibles a la cantidad e integridad de los datos entrantes. Al desplegar modelos en nuevos clientes, debemos garantizar que no haya diferencias importantes y significativas entre los datos locales y los datos en los que se han entrenado los modelos. El segundo aspecto a tener en cuenta es el decaimiento del modelo. El rendimiento de los modelos de aprendizaje automático en producción puede deteriorarse con el tiempo y empezar a comportarse de forma anómala porque los cambios en los datos de entrada reales provocan desviaciones entre la distribución de datos observada durante el entrenamiento del modelo y el entorno operativo.
Para mantener la precisión y fiabilidad de los modelos de aprendizaje automático a lo largo del tiempo, es obligatorio aplicar prácticas de operaciones de aprendizaje automático (MLOps) que impongan una supervisión periódica del rendimiento del sistema. Deben tomarse medidas proactivas para prevenir o mitigar las pérdidas de rendimiento, como el reentrenamiento o el ajuste fino del modelo con nuevos datos, a fin de superar las desviaciones del modelo o de los datos. Esto debe hacerse periódicamente, pero también en respuesta a cambios significativos en los datos, por ejemplo al enfrentarse a un nuevo cliente con escenarios novedosos e inéditos.
Pero a menudo nos enfrentamos al problema de la escasez de datos. Hay que reconocer un nuevo elemento específico, pero se dispone de muy pocos ejemplos a mano. Para hacer frente a este desafío, en AllRead contamos con una pila única de soluciones de aprendizaje profundo que utilizan técnicas de aumento de datos junto con la generación de datos sintéticos para que nuestros modelos estén expuestos a una gama amplia y representativa de datos, lo que los hace más robustos y resistentes a la variabilidad que nos encontramos, al tiempo que tienen la capacidad de ser ajustados para escenarios ad-hoc específicos a los que nos enfrentamos.
De manera similar, técnicas como el aprendizaje por transferencia (transfer learning) o la adaptación de dominio (domain adaptation), donde los modelos entrenados en una distribución de datos fuente se aplican a una distribución de datos diferente pero relacionada, ayudan a nuestros modelos a adaptarse a entornos en constante cambio y abordar casos de uso específicos.

4. Aplicando Machine Learning en Terminal 6 Argentina.
Situada a orillas del río Paraná, la Terminal 6 (T6) es el complejo agroindustrial exportador más importante de América Latina. El puerto recibe diariamente más de 80.000 toneladas de materias primas, que son almacenadas, transformadas y finalmente expedidas a diversas partes del mundo.
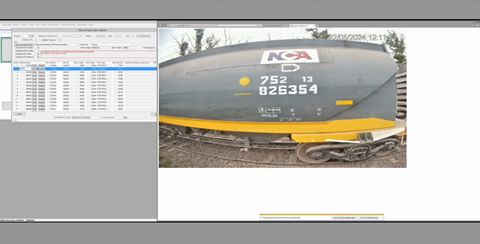
El transporte por tren representa el 33% del total. La terminal recibe diariamente unos 10 trenes cargados de grano, que cuentan con aproximadamente 50 vagones etiquetados con sus respectivos códigos de identificación. Los vagones deben ser identificados al menos dos veces, cuando entran en la terminal y cuando pasan por la báscula de pesaje para ser luego imputados en los sistemas de gestión de la información. Este proceso, realizado manualmente, tuvo que digitalizarse, dado que el proceso de recogida de datos representaba un cuello de botella para la T6 y corría el riesgo de cometer errores.

Los códigos de los vagones que se encuentran en estos trenes no son normas ISO, sino todo lo contrario, exclusivos de este caso de uso, por lo que no se disponía de ninguna solución robusta «de estante». El sistema debe ser capaz de reconocer dos tipos diferentes de códigos, además de enfrentarse a escenarios bastante desafiantes en términos de visibilidad/leibilidad de estos códigos, que a menudo están sucios o muy dañados.

La solución propuesta por AllRead implica el despliegue de dos modelos de IA diferentes. El primero es el modelo dedicado a detectar y reconocer los códigos de los vagones (A), mientras que el segundo modelo se utiliza para detectar los separadores de vagones (enganches) (B). Aunque algunos códigos de vagón son ilegibles, podemos ensamblar el mapa correcto del tren mediante la combinación de esos dos modelos en paralelo.

Para proporcionar rápidamente una solución operativa al cliente, primero desplegamos nuestros modelos genéricos de reconocimiento de texto en escena, capaces de detectar y reconocer cualquier texto presente en las imágenes. A continuación, un paso ad hoc de postprocesamiento identificó los códigos de los vagones a partir del resto del texto extraído.
Esta aplicación inicial arrojó unos resultados en torno al 80%. Algunos de los códigos no se detectaron correctamente, y el tipo de letra utilizado para imprimir los códigos en los vagones provocó que a menudo se reconocieran erróneamente los dígitos «5», «6» y «9» (véanse las imágenes anteriores). Aunque se disponía de pocos datos adicionales, era necesario volver a entrenar los modelos para hacer frente a la deriva de datos y modelos a la que nos enfrentábamos. Pusimos en marcha dos iteraciones del bucle MLOps, que implicaban la recopilación, pero sobre todo la síntesis de nuevos datos de entrenamiento, el ajuste fino y la adaptación al dominio de nuestros modelos de aprendizaje profundo para la detección y el reconocimiento de texto y la supervisión del rendimiento. Finalmente desplegamos una solución a medida para aquellos códigos de vagón específicos que proporcionaron precisiones superiores al 96% de reconocimiento.
La solución propuesta por AllRead se adaptaba perfectamente a lo que buscaba T6. Después de algunas iteraciones sobre los modelos iniciales desplegados, e independientemente del escenario desafiante, gracias a la robustez del software y sus modelos de IA, AllRead se mantiene fiel a su filosofía: garantizar siempre los requisitos mínimos de hardware: dos cámaras y dos puntos de luz fijados en postes a ambos lados del carril, y conectados a un servidor.

Con el apoyo de Generática, consultores tecnológicos del puerto y socio de AllRead, la solución se ha integrado en los sistemas de información y en las tareas diarias de los operadores. Teniendo en cuenta que a principios de 2024, mientras que el proceso de pesaje era digital, el seguimiento de los trenes se realizaba manualmente (es decir, para cada tren que entraba, se tomaban las notas manualmente para vincularlas después a sus respectivos pesos), se puede suponer la importante ganancia de eficiencia que supone automatizar la recogida y consolidación de datos.
Síganos y suscríbase a nuestro boletín
Para estar al día de las novedades de AllRead, suscríbase a nuestro boletín. Recibirá periódicamente los contenidos y noticias más relevantes de nuestro blog en la bandeja de entrada de su correo electrónico.
Síganos también en nuestros perfiles sociales de LinkedIn, Twitter y YouTube.